
Links:
- Source (Github repo, LWJGL license)
- JavaFX applet demo (+webstart link)
- JWS package (to run locally if you have trouble with the applet above)
- Windows installer (built with JavaFX native packaging)
Minimum requirements: Java 7 with JavaFX 2.2+, OpenGL 1.5+ with support for pixel buffer objects and framebuffer objects.
edit: It currently does not work on MacOS X.
Screenshot:
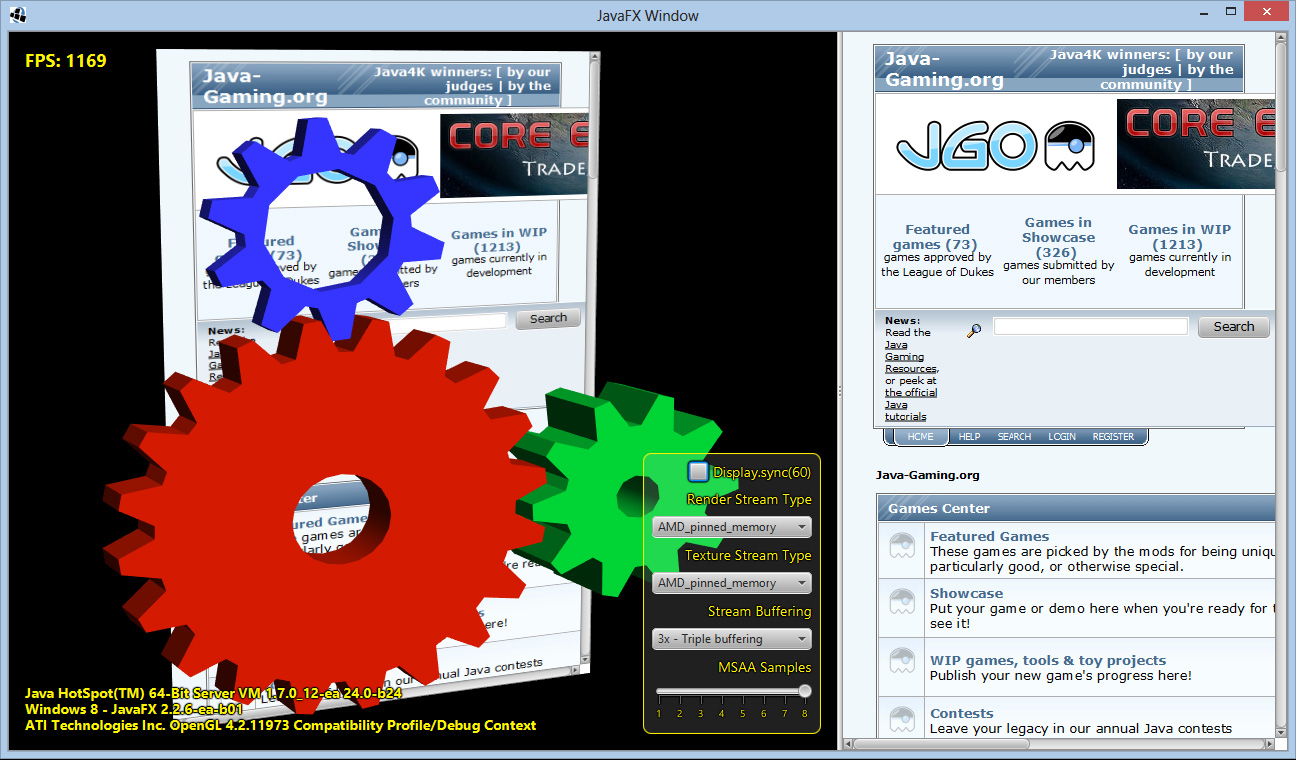
What’s going on in the demo?
-
An LWJGL 3D scene is rendered to an offscreen framebuffer and then displayed inside a JavaFX node. The integration is lightweight and you can have any other JavaFX node on top of the 3D scene.
-
A JavaFX node is rendered to an offscreen image, copied to a GL texture and then displayed inside the 3D scene. In this demo, the node happens to be a WebView that renders java-gaming.org. You can interact with the WebView and the texture will update accordingly.
Please report any problems (won’t start, crashes, bad performance) and feel free to check out the source code. I’ve tried to make it general enough so that it can be used in windowing toolkits other than JavaFX (e.g. with AWT).
If you try the windows installer and run into problems, try running the executable from the command-line with /Debug.
