Nothing crazy, just updated the default button style in LWJGUI light theme

Nothing crazy, just updated the default button style in LWJGUI light theme
I went to my local vintage video game store and got 2 sonic games for PC. I need Windows 95 or a DOS box. I’m gonna try to install windows 95 on an old computer, just to see if I can.
Added a nicer insert gui in AnarchyEngine
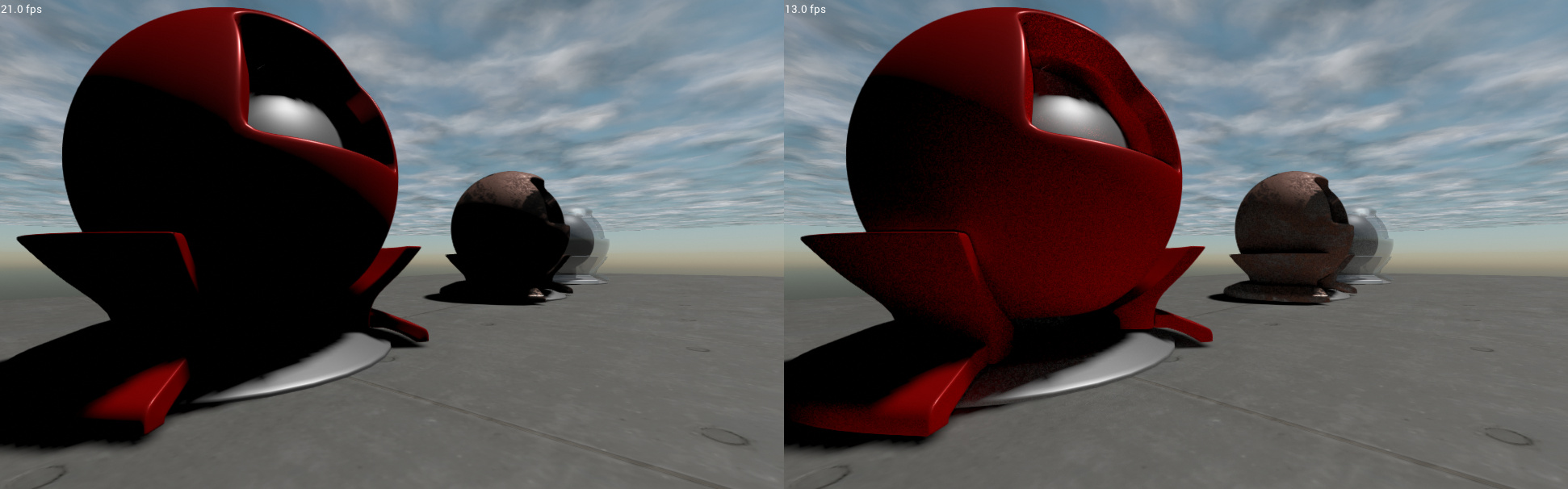
Implemented ray march screen-space global illumination using the same code from the AO, which I’ve also improved.
Debug view, missing hit depth and normal checks.
Final look.
Added depth check to AO, fixed color calculation. (Before, After)
I need a blur/denoise pass asap.
Changed the backing data store of the matrix from float array to a direct ByteBuffer (so we can hand the matrix to native libraries like OpenGL with zero-copy!) and runtime of the following code was ~33ns/op. So, I built the hsdis library from the panama vectorIntrinsics branch and analyzed why the following code performs worse than simple scalar multiplication followed by sun.misc.Unsafe puts of the float members into a ByteBuffer:
private static final VectorShuffle<Float> s0 = SPECIES_128.shuffleFromValues(0, 0, 0, 0);
private static final VectorShuffle<Float> s1 = SPECIES_128.shuffleFromValues(1, 1, 1, 1);
private static final VectorShuffle<Float> s2 = SPECIES_128.shuffleFromValues(2, 2, 2, 2);
private static final VectorShuffle<Float> s3 = SPECIES_128.shuffleFromValues(3, 3, 3, 3);
private final ByteBuffer es = ByteBuffer.allocateDirect(16*4).order(ByteOrder.nativeOrder());
public Matrix4fv mul(Matrix4fv o) {
FloatVector row1 = FloatVector.fromByteBuffer(SPECIES_128, o.es, 0, n);
FloatVector row2 = FloatVector.fromByteBuffer(SPECIES_128, o.es, 16, n);
FloatVector row3 = FloatVector.fromByteBuffer(SPECIES_128, o.es, 32, n);
FloatVector row4 = FloatVector.fromByteBuffer(SPECIES_128, o.es, 48, n);
for (int i = 0; i < 4; i++) {
FloatVector r = FloatVector.fromByteBuffer(SPECIES_128, es, i<<4, n);
r.rearrange(s0).fma(row1,
r.rearrange(s1).fma(row2,
r.rearrange(s2).fma(row3,
r.rearrange(s3).mul(row4))))
.intoByteBuffer(es, i<<4, n);
}
return this;
}
It all comes down to a TON of index and other validation checks for FloatVector.rearrange() and fromByteBuffer/intoByteBuffer calls (even in C2). Java really wants to be save here and obviously not crash with a hardware exception, instead of generating high-performance code. Yes, there is this JVM property that you can set to eliminate out-of-bounds checks, but that does not disable every check. So, I guess, if you want really fast SIMD code, the JVM is not the platform of choice; or you patch the JDK classes and remove all index checks. 
The latter is certainly doable by the way and the JDK build process has become ridiculously simple: bash configure (once) and then make images.
The other thing that hampers performance severly is the fact that the Vector API uses runtime values “vector species” to decide at runtime which kind of vector you are operating on. A 128, 256 or 512 bit vector. This species information is dragged through all calls and evaluated whenever a native intrinsic is to be called, which can also be seen in the disassembly. You cannot say: Here, this is a Float128Vector (this class is package-private in the JDK and selected based on the “species” at runtime). This is stupid. Maybe the compiler will take care of this in the future by eliminating values that it knows are constant at the callsite.
There is also a nice comment on the vspecies() method which is called to know the “species” of a runtime vector instance:
public FloatSpecies vspecies() {
// ISSUE: This should probably be a @Stable
// field inside AbstractVector, rather than
// a megamorphic method.
return VSPECIES;
}
YES?!
After I eliminated all rearrange and fromByteBuffer/toByteBuffer index checks in the JDK’s source of FloatVector, runtime got down from ~33 ns/op for this ByteBuffer backed method to ~16ns/op, making it faster than the float-field-based scalar version storing into ByteBuffer at the end (which was ~23 ns/op).
EDIT: When using an AVX version of a 4x4 multiply from https://stackoverflow.com/questions/19806222/matrix-vector-multiplication-in-avx-not-proportionately-faster-than-in-sse#answer-46058667 then speedup is even greater. Also, without any index checks, an equivalent Java Vector API code gets the read-from-direct-bytebuffer + 4x4 multiply + store-into-direct-bytebuffer in ~11 ns/op.
Super-fast multiplication:
public Matrix4fv mul256(Matrix4fv o) {
FloatVector t0 = FloatVector.fromByteBuffer(SPECIES_256, es, 0, n),
t1 = FloatVector.fromByteBuffer(SPECIES_256, es, 32, n);
FloatVector u0 = FloatVector.fromByteBuffer(SPECIES_256, o.es, 0, n),
u1 = FloatVector.fromByteBuffer(SPECIES_256, o.es, 32, n);
t0.rearrange(s4)
.fma(u0.rearrange(s5), t0.rearrange(s6).mul(u0.rearrange(s7)))
.add(t0.rearrange(s9).fma(u1.rearrange(s7), t0.rearrange(s8).mul(u1.rearrange(s5))))
.intoByteBuffer(es, 0, n);
t1.rearrange(s4)
.fma(u0.rearrange(s5), t1.rearrange(s6).mul(u0.rearrange(s7)))
.add(t1.rearrange(s9).fma(u1.rearrange(s7), t1.rearrange(s8).mul(u1.rearrange(s5))))
.intoByteBuffer(es, 32, n);
return this;
}
For anyone wanting to follow the performance of the Panama Vector API project, I’ve created a repo which I will update from time to time when significant changes happen to Panama’s vectorIntrinsics branch: https://github.com/JOML-CI/panama-vector-bench

is anyone coming…?
Wired in the UI.
Hud

Consumables (health flask)

Passive skills

Equipment and crafting

Implemented real time voxelization for global illumination.


As before, not optimized in any way and can be improved. Specially the voxelization, still does some weird things to geometry.
I discovered this insane bundle today, and I can’t not post about it. Maybe someone feels generous and wants to add their game(s)?
Not necessarily what I’ve done today, but I’ve been working on a multiplayer rogue-like and so far it’s coming along quite nicely. Today I’ve added MySQL database functionality.


Woohoo…transfer is complete
This has absolutely nothing to do with Java or gaming, but I’m pretty proud of it still: Today I’ve passed the AWS Certified Solutions Architect - Associate (SAA-C02) exam, after having worked with AWS with a large retail customer for 18 months and actively prepared for the exam for about a year with various online courses and all study books I could find. Next step is the Solutions Architect - Professional exam to learn how to help customers to build up their AWS architectures and not help them operate on them after the fact.
Still getting used to the new format of this forum!
I got an old TODO item off of my list today. When I dropped my old web host late last year and started up with Linode, I was only able to get one of my domains working. Today I finally have Jetty serving both domains. Figuring out the proper configuration was tricky. I can’t say that I find either the documentation provided by Linode or Jetty very easy to work with. Fortunately there were people on forums for both that were able and willing to help!
A lot of the links that I have here at jvm-gaming have been “dead” during this period. I just did some spot checks, and while the jpgs are not displaying, at least clicking on the link now brings up the image. Most of this pertains to content I posted years ago, and is probably getting very few views anyway. Am just glad to finally figure it out.
I’ve begun porting utility stuff from the LWJGL 3 ray tracing demos over to a new WebGL 2.0 TypeScript project with the help of the JSweet online transpiler and was worried about the performance of the JavaScript code compared to the JVM Bytecode, especially since the code uses some bit-twiddling on explicitly-sized integer types. I thought maybe WebAssembly would be the way to go with that, but did not want to actually code in C/C++ and preferably stay in the TypeScript world. And I just found out about AssemblyScript… what an awesome project! Special types for all the different-sized primitive data types. So, coding in TypeScript with explizit sized integer types and compile to WebAssembly! I’ve yet to figure out how seamless the interoperability with TypeScript and AssemblyScript is.
Started playing around with libgdxAI which always follows the player until it’s standing next to him in a round based game prototype thing.
MyGdxGame 2020-07-21 13-45-07
I’ve begun porting utility stuff from the LWJGL 3 ray tracing demos over to a new WebGL 2.0 TypeScript project with the help of the JSweet online transpiler and was worried about the performance of the JavaScript code compared to the JVM Bytecode
I’ve been using JSweet for porting stuff to Javascript over the last 6 months too. It’s been a tough learning experience for me since I barely know any javascript. At least by using JSweet I can learn the javascript libraries without having to learn the language.
I chose JSweet over GWT and J2CL https://github.com/google/j2cl due to it being more lightweight and easier to get started. But the compile time is a real bummer: java to typescript to javascript which takes tens of seconds for every little change.
I’ve found that drawing performance on all browsers is quite good using just the HTML Canvas. My basic 2D games achieve 60fps.
I’m interested to follow your adventures in WebAssembly.
I’ve released GLIntercept 1.3.5, a fork from Damian Trebilco project :
https://github.com/YvesBoyadjian/glintercept/releases
This new version supports multithreaded access to OpenGL, and also, can be chained with Mesa3D software renderer for Windows :