
Not too long ago, we were having a discussion about binaural sound effects, and Riven wrote about the technique of introducing a time difference between the left and right tracks to create a pan effect.
I wanted to investigate this further, so I wrote a program to compare two ways of creating stereo:
- by having a mono signal be given different volumes in each ear
- by having a mono signal be given with a time difference in each ear
Jar file, with source code is here
I put in a couple different source sounds:
- sine wave, with ability to specify the Hertz and the length of time in seconds (can test specific ranges–supposedly the time effect works best with low notes and the volume effect works best with high notes)
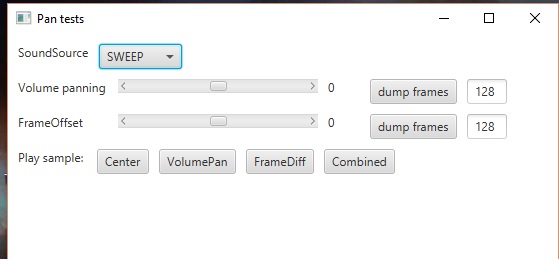
- sine sweep, from low to high (about 4 seconds long)
- frog sample (recorded from a local creek, saved as a mono array of PCM floats in the range -1 to 1)
There are two sliders:
- volume panning, uses the following formula to convert the slider value (“volumePan”) to channel factors:
float pan = (volumePan + 1) / 2;
for (int i = 0; i < size; i++)
{
stereoPcmSample[i * 2] = pcmSample[i] * (1 - pan);
stereoPcmSample[i * 2 + 1] = pcmSample[i] * pan;
}
- sound frame differences, which can range from -128 to 128 (if negative, left channel leads by given number of frames, if positive, right channel leads by given number of frames).
For reference, a sound frame here is 1/44100th of a second, or approximately 0.000_023 seconds in length.
Another reference, the distance sound can typically travel in air is 343.59 meters per second. So, in one frame, we have 343.59/44100 equal to approximately 0.78 centimeters.
Thus, the distance from one ear to another should consume, what? (jokes about fat heads not needed)
I get about 30 cm if I roll a ruler around my head. What does that come to? 36 frames for the biggest time difference between the two ears?
In fact, when I was listening to this with headphones, I was putting the left-most or right-most setting of the framediff slider at between 32 to 36 (or -32 to -36). So, I am pleased this calculation seems to come out. Making the difference larger than that didn’t seem to increase the location towards the sides.
I found the “frog croak” to be the clearest example. With the sweeping tone, it seems like the location may move around a bit as a function of the pitch with the time-difference method. Not sure how to account for this.
Is it my imagination or wishful thinking that putting the frog at a location to the side, and matching it as best as possible with the volume-pan, that the time-difference method sounds a bit cleaner somehow?
Feedback much desired. I made the code available in the jar so folks could verify what is being presented. As always, as a musician who taught himself Java, any suggestions on the coding itself are also appreciated (either on this thread or as personal messages).